Abstract
Scaling laws with respect to the amount of training data and the number of parameters allow us to predict the cost-benefit trade-offs of pretraining language models (LMs) in different configurations. In this paper, we consider another dimension of scaling: the amount of data available at inference time. Specifically, we find that increasing the size of the datastore used by a retrieval-based LM monotonically improves language modeling and several downstream tasks without obvious saturation, such that a smaller model augmented with a large datastore outperforms a larger LM-only model on knowledge-intensive tasks. By plotting compute-optimal scaling curves with varied datastore, model, and pretraining data sizes, we show that using larger datastores can significantly improve model performance for the same training compute budget.
We carry out our study by constructing a 1.4 trillion-token datastore named MassiveDS, which is the largest and the most diverse open-sourced datastore for retrieval-based LMs to date, and designing an efficient pipeline for studying datastore scaling in a computationally accessible manner. Finally, we analyze the effect of improving the retriever, datastore quality filtering, and other design choices on our observed scaling trends. Overall, our results show that datastore size should be considered as an integral part of LM efficiency and performance trade-offs. To facilitate future research, we open-source all artifacts.
MassiveDS and our Datastore Scaling Pipeline
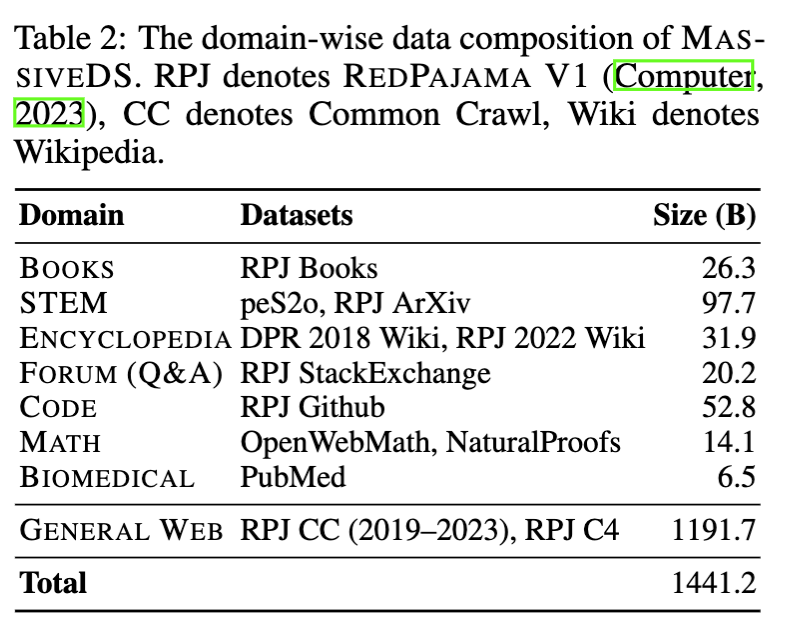
MassiveDS MassiveDS is constructed from diverse data sources including both domain-specific data and massive web data (Table 2), so that it can benefit a wide range of tasks.
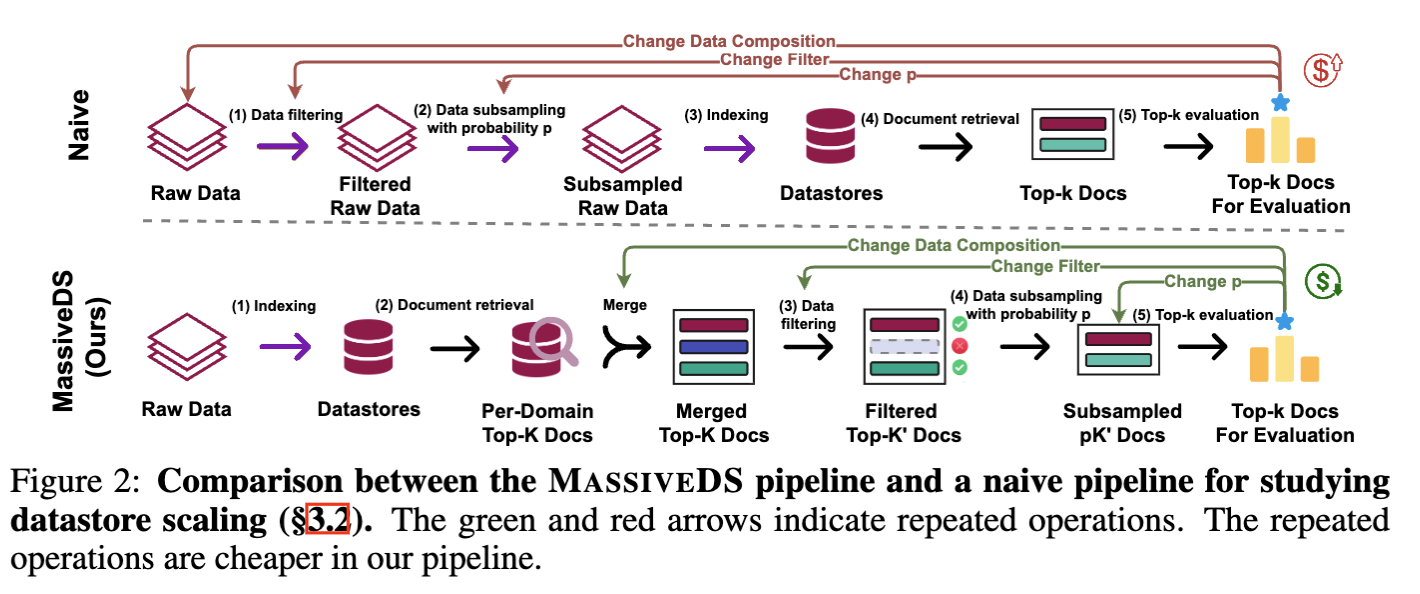
We also designed an efficient scaling experiment pipeline (Figure 2) that lets us understand scaling trends on an academic budget. The key idea is to reorder the operations to make the repeated ones cheaper. We prove its equivalence to the naive implementation in Appendix A.
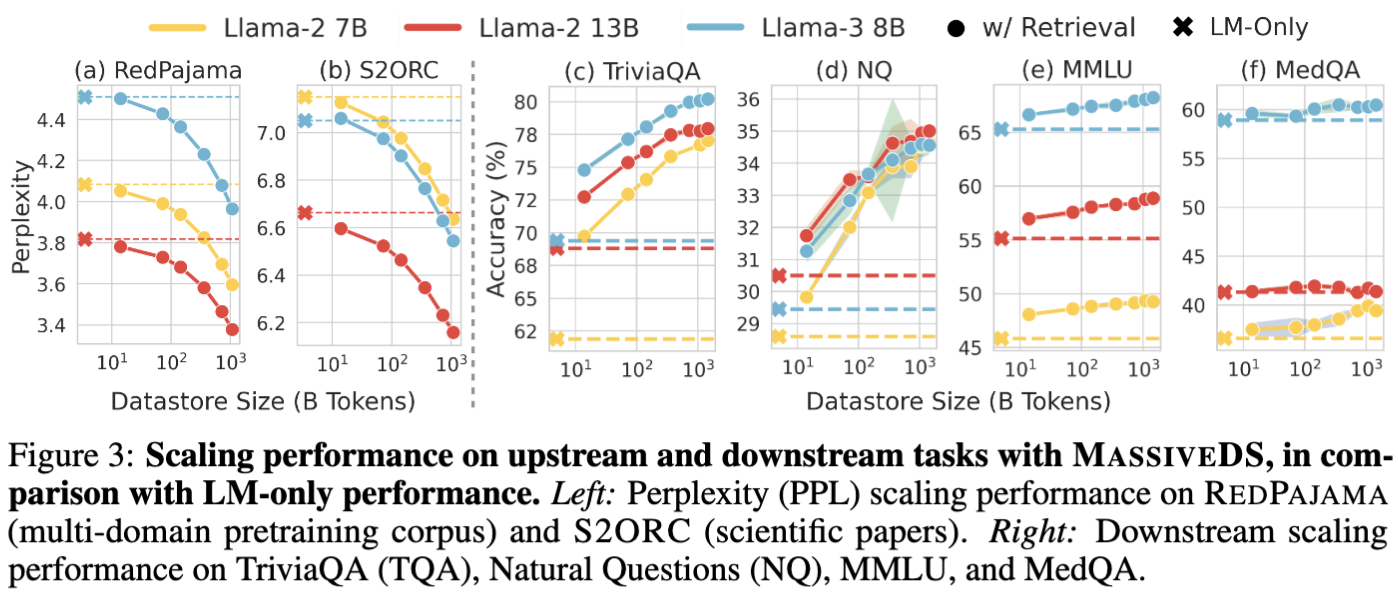
Scaling Trends
Datastore Scaling
Previous work has shown scaling datastore is helpful for language modeling, while it remains unknown how it applies to downstream tasks. We show MassiveDS not only helps language modeling but also downstream tasks including MMLU.
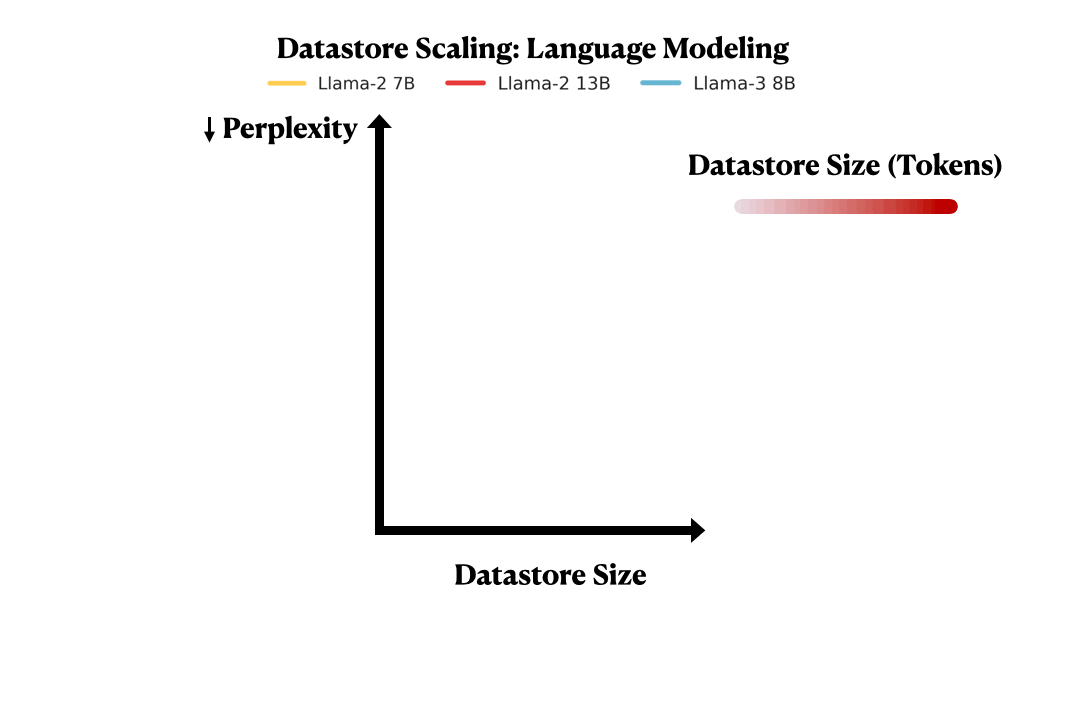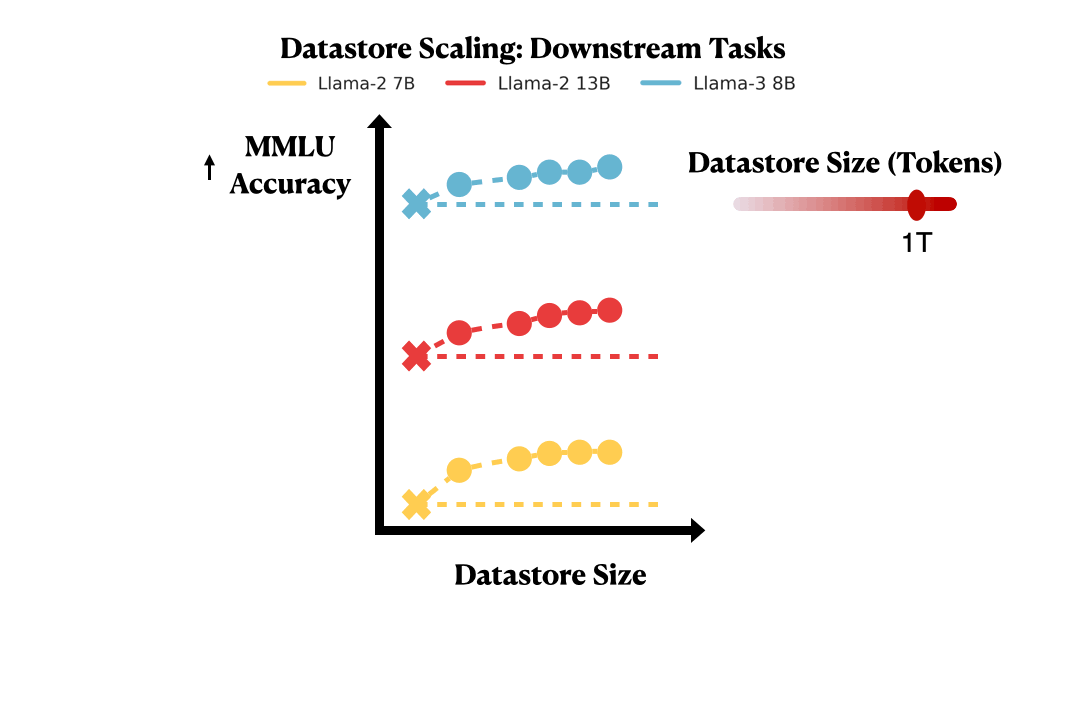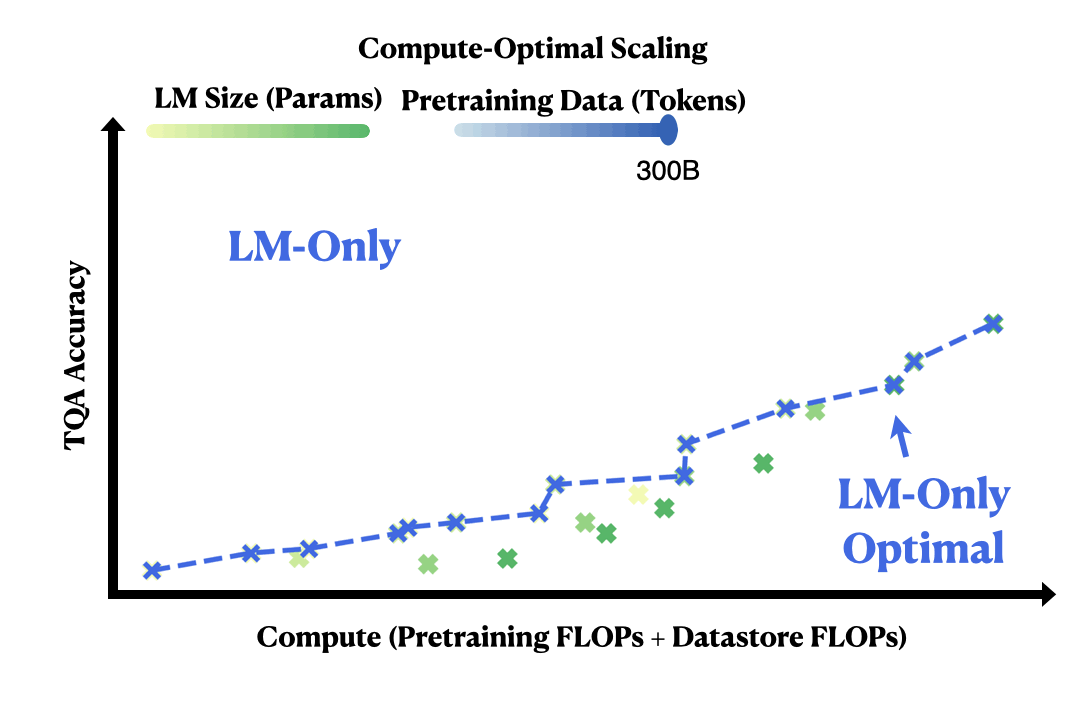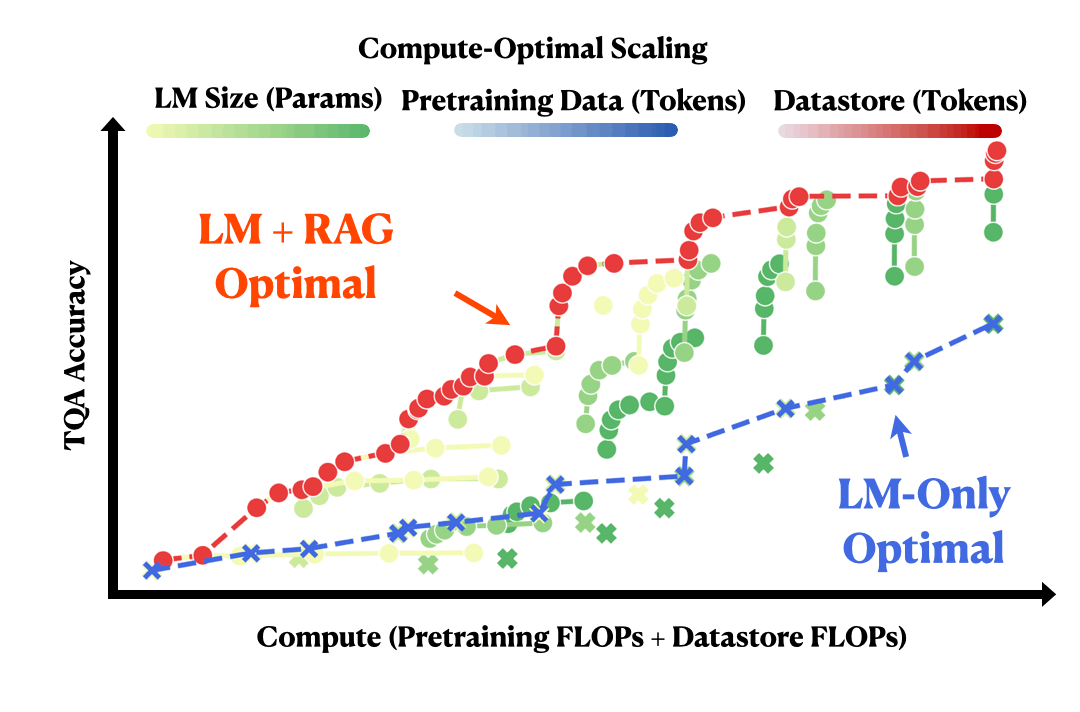
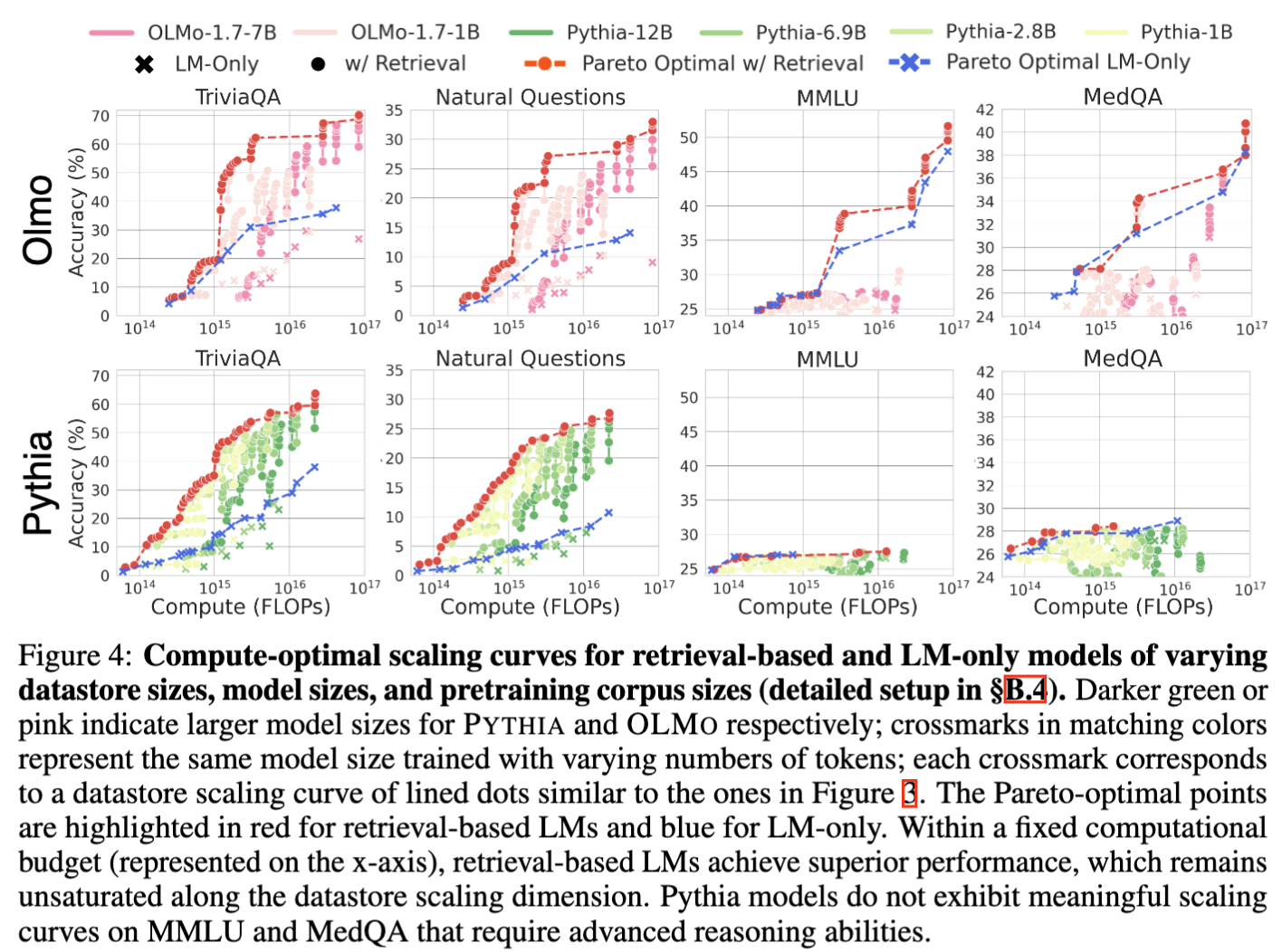
Compute-Optimal Scaling
We find using larger datastores can significantly improve performance for the same training compute. Figure 4 shows compute-optimal scaling curves with OLMo and Pythia on 4 downstream tasks.
Analysis
Retriever is Robust to Out-of-Distribution Data in the Datastore
We compare the performance of MassiveDS with single-domain datastores in Table 3. The results show that MassiveDS matches or outperforms all single-domain datastores.
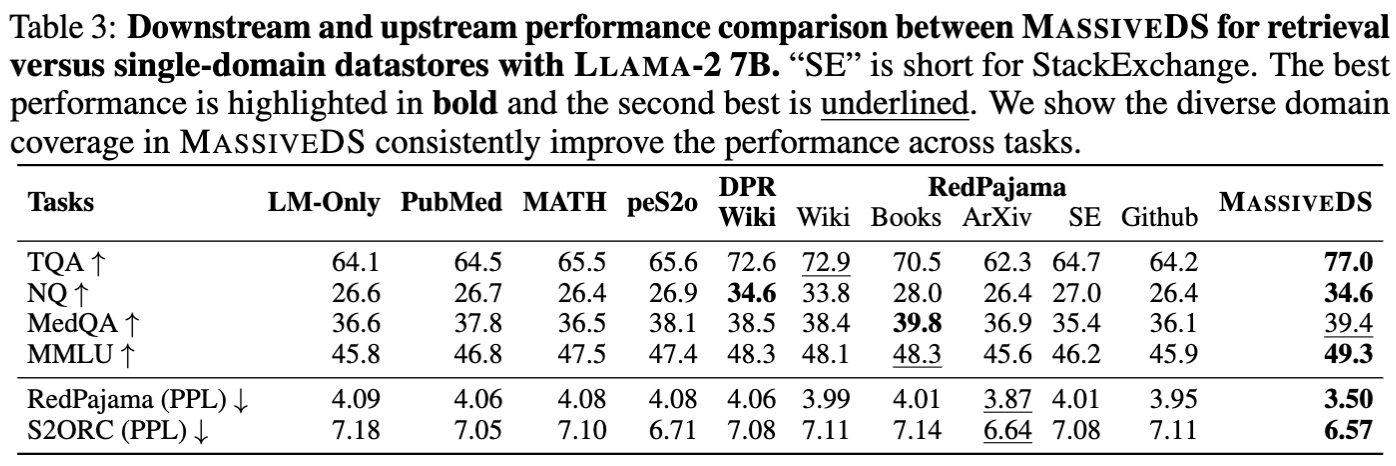
We further investigate the source of this robustness and find that the retriever tends to retrieve more from the relevant domain depite the the existance of a large amout of out-of-distribution data, as shown in Figure 5.
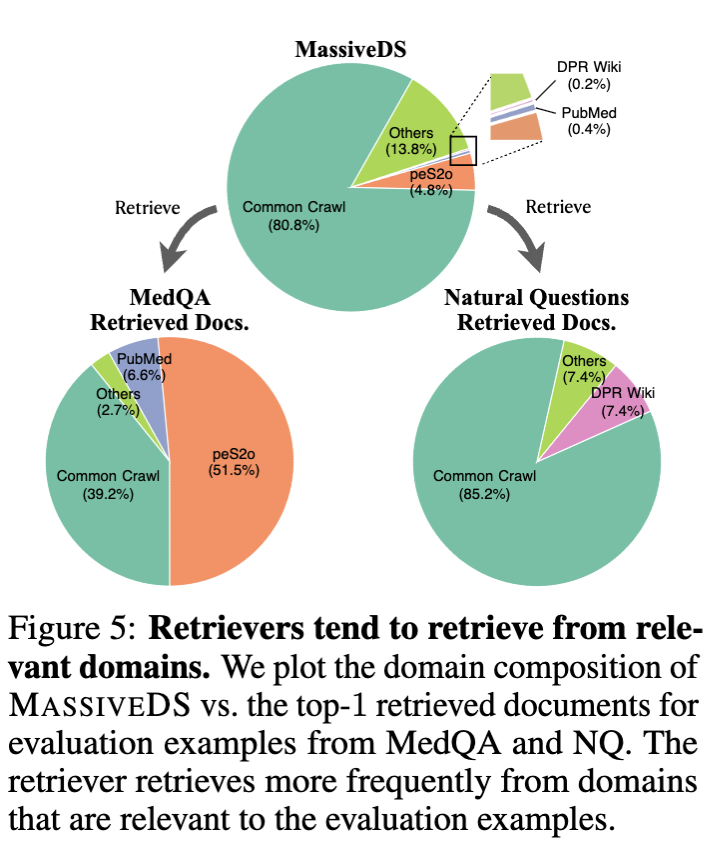
Overall, these results show that retrieving from broad datastores like MassiveDS can simultaneously improve performance across multiple domains, paving the path towards general-purpose retrieval-based models.
Impact of Reranker and Data Contamination
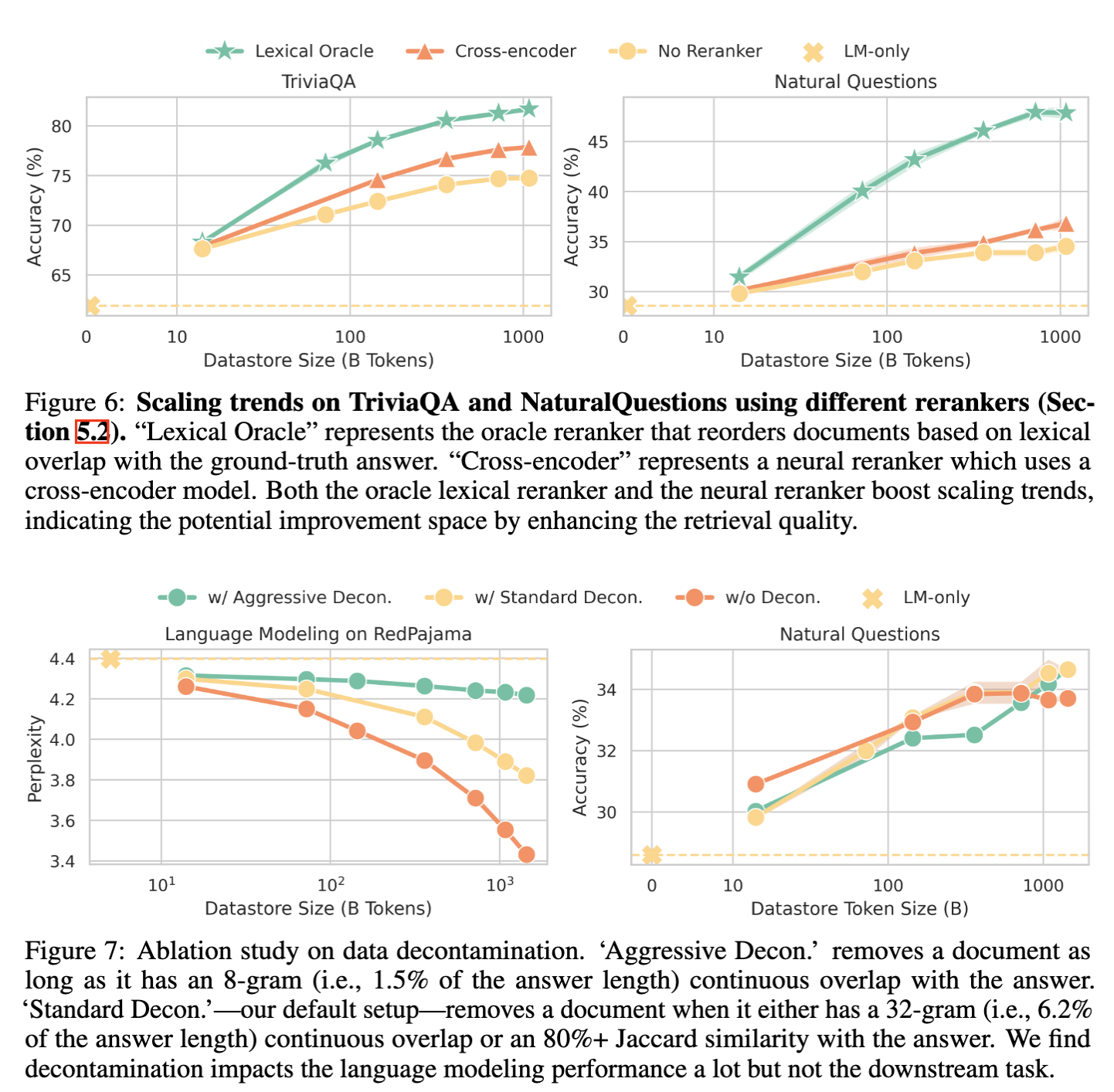
As shown in Figure 6, we find scaling trends can be improved with advanced retrieval, such as reranking. In addition, we find data contamination has a large impact on language modeling evaluation, as shown in Figure 7, so we advocate applying strict decontamination for RAG perplexity evaluation.
Future Directions
Our compute-optimal scaling trends indicate that retrieval-based language models (LMs) scale better than standalone LMs. Based on these findings, future research could focus on designing more effective training resource allocation strategies for retrieval-based LMs.
We demonstrate that storing trillion-token data in a datastore can effectively enhance language modeling and several downstream tasks. This approach introduces new challenges in serving retrieval-based language models (LMs) and highlights the need for efficient serving of large-scale datastores coupled with LMs. Future work could utilize MassiveDS to test new efficient index structures and systems.
There has been ongoing discussion comparing retrieval-based LMs to long-context LMs. Our work relates to this in that we retrieve data from trillions of tokens and prepend it to the context, which can be seen as a method to achieve a 1-trillion-token context length through a sparse context selection process. On the other hand, using a long-context LM enables us to include more retrieved tokens within the context. We are curious about potential follow-ups in this direction.
Reprduction and Datastore
All code is available at Github, and all datastore artifacts are available at Huggingface Space.
BibTeX
@article{shao2024scaling,
title={Scaling Retrieval-Based Language Models with a Trillion-Token Datastore},
author={Shao, Rulin and He, Jacqueline and Asai, Akari and Shi, Weijia and Dettmers, Tim and Min, Sewon and Zettlemoyer, Luke and Koh, Pang Wei},
journal={arXiv preprint arXiv:2407.12854},
year={2024}
}